because it creates new attack surfaces, new opportunities for bugs, and is very unlikely to accurately deal with all of the edge cases.
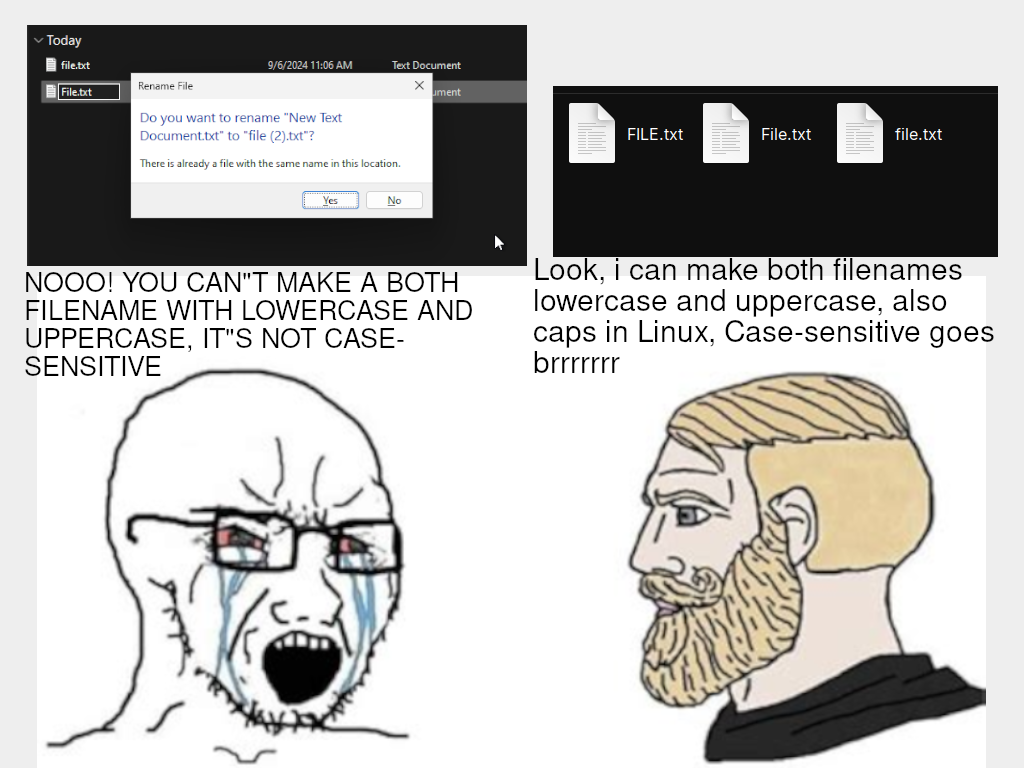
Unicode case folding has been a solved problem for a long time. The Unicode standard has rules for which characters should be considered identical, and many libraries exist to handle it (you wouldn’t ever code this yourself).


{kind=link}
Unicode case folding has been a solved problem for a long time. The Unicode standard has rules for which characters should be considered identical, and many libraries exist to handle it (you wouldn’t ever code this yourself).